稳定扩散 webUI
基于用于稳定扩散的 Gradio 库的浏览器界面。
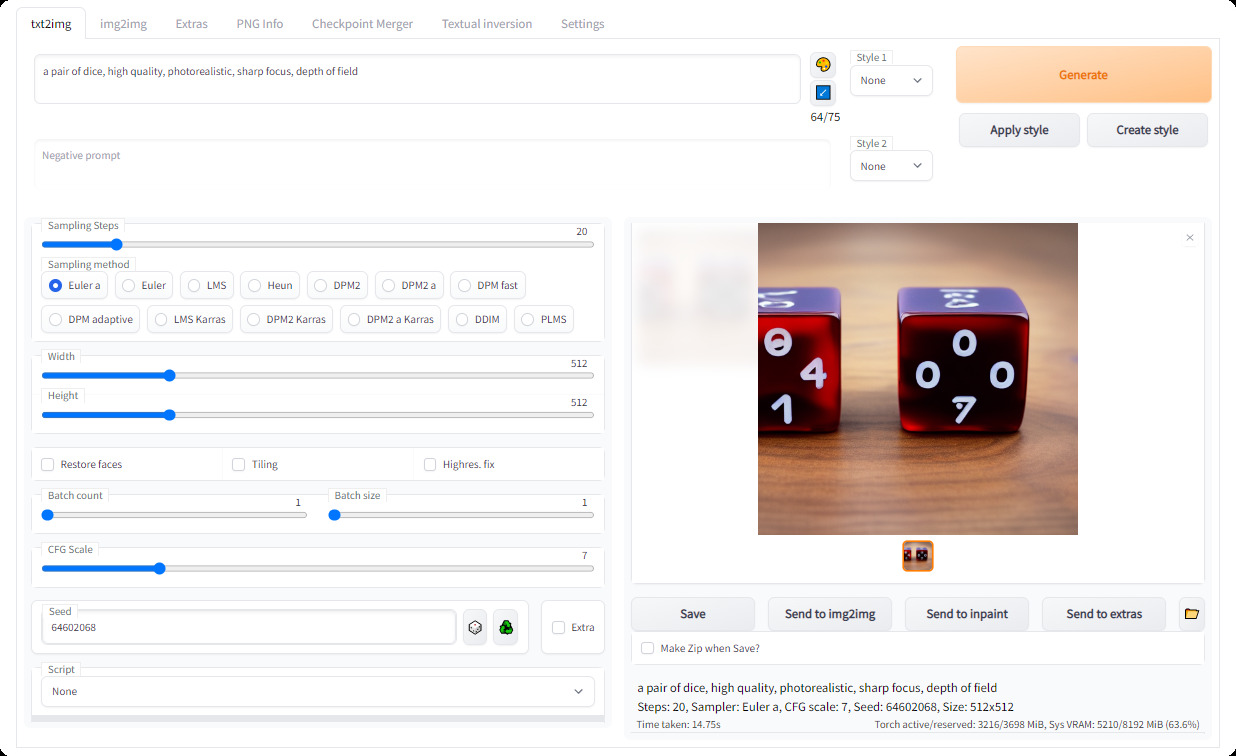
查看 自定义脚本 wiki 页面以获取用户开发的额外脚本。
## 特征 带有图像的详细功能展示:
- 原始的 txt2img 和 img2img 模式
- 一键安装并运行脚本(但您仍然必须安装 python 和 git)
- 涂装
- 修复
- 彩色素描
- 提示矩阵
- 稳定扩散高档
- 注意,指定模型应该更加注意的文本部分
- a man in a ((tuxedo)) - 会更加注意燕尾服
- 一个穿燕尾服的男人 (tuxedo:1.21) - 替代语法
- 选择文本并按 ctrl+up 或 ctrl+down 自动调整对所选文本的关注(代码由匿名用户提供)
- Loopback,多次运行img2img处理
- X/Y 图,一种绘制具有不同参数的二维图像图的方法
- 文本倒置
- 拥有任意数量的嵌入,并为它们使用任何你喜欢的名称
- 使用每个标记具有不同数量向量的多个嵌入
- 适用于半精度浮点数
- 在 8GB 上训练嵌入(还有 6GB 工作的报告)
- 附加选项卡:
- GFPGAN,修复人脸的神经网络
- CodeFormer,面部修复工具作为 GFPGAN 的替代品
- RealESRGAN,神经网络升级器
- ESRGAN,具有大量第三方模型的神经网络升级器
- SwinIR 和 Swin2SR(见此处),神经网络升频器
- LDSR,潜在扩散超分辨率升级
- 调整宽高比选项
- 取样方法选择
- 调整采样器 eta 值(噪声倍增器)
- 更高级的噪音设置选项
- 随时中断处理
- 4GB 视频卡支持(还有 2GB 工作报告)
- 正确的批次种子
- 实时提示令牌长度验证
- 生成参数
- 用于生成图像的参数与该图像一起保存
- 在 PNG 的 PNG 块中,在 JPEG 的 EXIF 中
- 可将图片拖拽至PNG信息标签,恢复生成参数并自动复制到UI中
- 可以在设置中禁用
- 将图像/文本参数拖放到提示框
- 读取生成参数按钮,将提示框中的参数加载到 UI
- 设置页面
- 从 UI 运行任意 python 代码(必须使用 –allow-code 运行才能启用)
- 大多数 UI 元素的鼠标悬停提示
- 可以通过文本配置更改 UI 元素的默认值/混合/最大/步进值
- 随机艺术家按钮
- 平铺支持,用于创建可以像纹理一样平铺的图像的复选框
- 进度条和实时图像生成预览
- 否定提示,一个额外的文本字段,允许您列出您不想在生成的图像中看到的内容
- 样式,一种保存部分提示并稍后通过下拉列表轻松应用它们的方法
- 变体,一种生成相同图像但有微小差异的方法
- 调整种子大小,一种生成相同图像但分辨率略有不同的方法
- CLIP 询问器,一个尝试从图像中猜测提示的按钮
- Prompt Editing,一种改变prompt mid-generation的方法,说开始制作西瓜并中途切换到动漫女孩
- 批处理,使用 img2img 处理一组文件
- Img2img Alternative, reverse Euler method of cross attention control
- Highres Fix,一个方便的选项,可以一键生成高分辨率图片而不会出现通常的失真
- 即时重新加载检查点
- 检查点合并,一个允许您将最多 3 个检查点合并为一个的选项卡
- 自定义脚本 具有来自社区的许多扩展
- Composable-Diffusion,一种同时使用多个提示的方法
- 使用大写的
AND分隔提示 - 还支持提示权重:
a cat :1.2 AND a dog AND a penguin :2.2 - 提示没有令牌限制(原始稳定扩散让您最多使用 75 个令牌)
- DeepDanbooru 集成,为动漫提示创建 danbooru 风格标签
- xformers,选择卡片的主要速度提升:(添加 –xformers 到命令行参数)
- 通过扩展:历史选项卡:在 UI 中方便地查看、定向和删除图像
- 生成永久选项
- 培训标签
- 超网络和嵌入选项
- 预处理图像:使用 BLIP 或 deepdanbooru(用于动漫)裁剪、镜像、自动标记
- 剪辑跳过
- 使用超网络
- 使用 VAE
- 进度条中的预计完成时间
- 应用程序接口
- 支持 RunwayML 的专用修复模型。
- 通过扩展:Aesthetic Gradients,一种通过使用剪辑图像嵌入生成具有特定美感的图像的方法(https: //github.com/vicgalle/stable-diffusion-aesthetic-gradients)
- 稳定扩散 2.0 支持 - 请参阅 wiki 的说明
安装和运行
确保满足所需的 dependencies 并遵循适用于 NVidia 的说明/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs)(推荐)和 [AMD](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and -在 AMD-GPU 上运行)GPU。
或者,使用在线服务(如 Google Colab):
在 Windows 上自动安装
- 安装Python 3.10.6,勾选“Add Python to PATH”
- 安装 git。
- 下载 stable-diffusion-webui 存储库,例如通过运行
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git。 - 将
model.ckpt放在models目录中(参见 dependencies 获取它的位置)。 -
*(可选)* 将
GFPGANv1.4.pth与webui.py放在基本目录中(参见 [dependencies](https://github.com/AUTOMATIC1111/stable-diffusion-webui/ wiki/Dependencies)获取它的位置)。 - 以普通非管理员用户身份从 Windows 资源管理器运行
webui-user.bat。
在 Linux 上自动安装
1.安装依赖:
# Debian-based:
sudo apt install wget git python3 python3-venv
# Red Hat-based:
sudo dnf install wget git python3
# Arch-based:
sudo pacman -S wget git python3
- 要安装在
/home/$(whoami)/stable-diffusion-webui/,运行:bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)
在 Apple Silicon 上安装
此处 找到说明。
贡献
以下是向此存储库添加代码的方法:贡献
文档
文档已从本自述文件移至项目的 wiki。
##学分
- 稳定扩散 - https://github.com/CompVis/stable-diffusion, https://github.com/CompVis/taming-transformers
- k-diffusion - https://github.com/crowsonkb/k-diffusion.git
- GFPGAN - https://github.com/TencentARC/GFPGAN.git
- CodeFormer - https://github.com/sczhou/CodeFormer
- ESRGAN - https://github.com/xinntao/ESRGAN
- SwinIR - https://github.com/JingyunLiang/SwinIR
- Swin2SR - https://github.com/mv-lab/swin2sr
- LDSR - https://github.com/Hafiidz/latent-diffusion
- MiDaS - https://github.com/isl-org/MiDaS
- 优化思路 - https://github.com/basujindal/stable-diffusion
- 交叉注意层优化 - Doggettx - https://github.com/Doggettx/stable-diffusion,快速编辑的原创想法。
- 交叉注意层优化 - InvokeAI,lstein - https://github.com/invoke-ai/InvokeAI(原 http://github.com/lstein/stable-diffusion)
- Textual Inversion - Rinon Gal - https://github.com/rinongal/textual_inversion(我们没有使用他的代码,但我们正在使用他的想法)。
- SD 高档的想法 - https://github.com/jquesnelle/txt2imghd
- 为 outpainting mk2 生成噪音 - https://github.com/parlance-zz/g-diffuser-bot
- CLIP 审讯器的想法和借用一些代码 - https://github.com/pharmapsychotic/clip-interrogator
- 可组合扩散的想法 - https://github.com/energy-based-model/Compositional-Visual-Generation-with-Composable-Diffusion-Models-PyTorch
- xformers - https://github.com/facebookresearch/xformers
- DeepDanbooru - 动漫扩散器审讯器 https://github.com/KichangKim/DeepDanbooru
- 安全建议 - RyotaK
- 初始 Gradio 脚本 - 由匿名用户发布在 4chan 上。谢谢匿名用户。
- (你)