Custom scripts
Installing and Using Custom Scripts
To install custom scripts, place them into the scripts directory and click the Reload custom script button at the bottom in the settings tab. Custom scripts will appear in the lower-left dropdown menu on the txt2img and img2img tabs after being installed. Below are some notable custom scripts created by Web UI users:
Custom Scripts from Users
Improved prompt matrix
https://github.com/ArrowM/auto1111-improved-prompt-matrix
This script is advanced-prompt-matrix modified to support batch count. Grids are not created.
Usage:
Use < > to create a group of alternate texts. Separate text options with |. Multiple groups and multiple options can be used. For example:
An input of a <corgi|cat> wearing <goggles|a hat>
Will output 4 prompts: a corgi wearing goggles, a corgi wearing a hat, a cat wearing goggles, a cat wearing a hat
When using a batch count > 1, each prompt variation will be generated for each seed. batch size is ignored.
txt2img2img
https://github.com/ThereforeGames/txt2img2img
Greatly improve the editability of any character/subject while retaining their likeness. The main motivation for this script is improving the editability of embeddings created through Textual Inversion.
(be careful with cloning as it has a bit of venv checked in)

txt2mask
https://github.com/ThereforeGames/txt2mask
Allows you to specify an inpainting mask with text, as opposed to the brush.
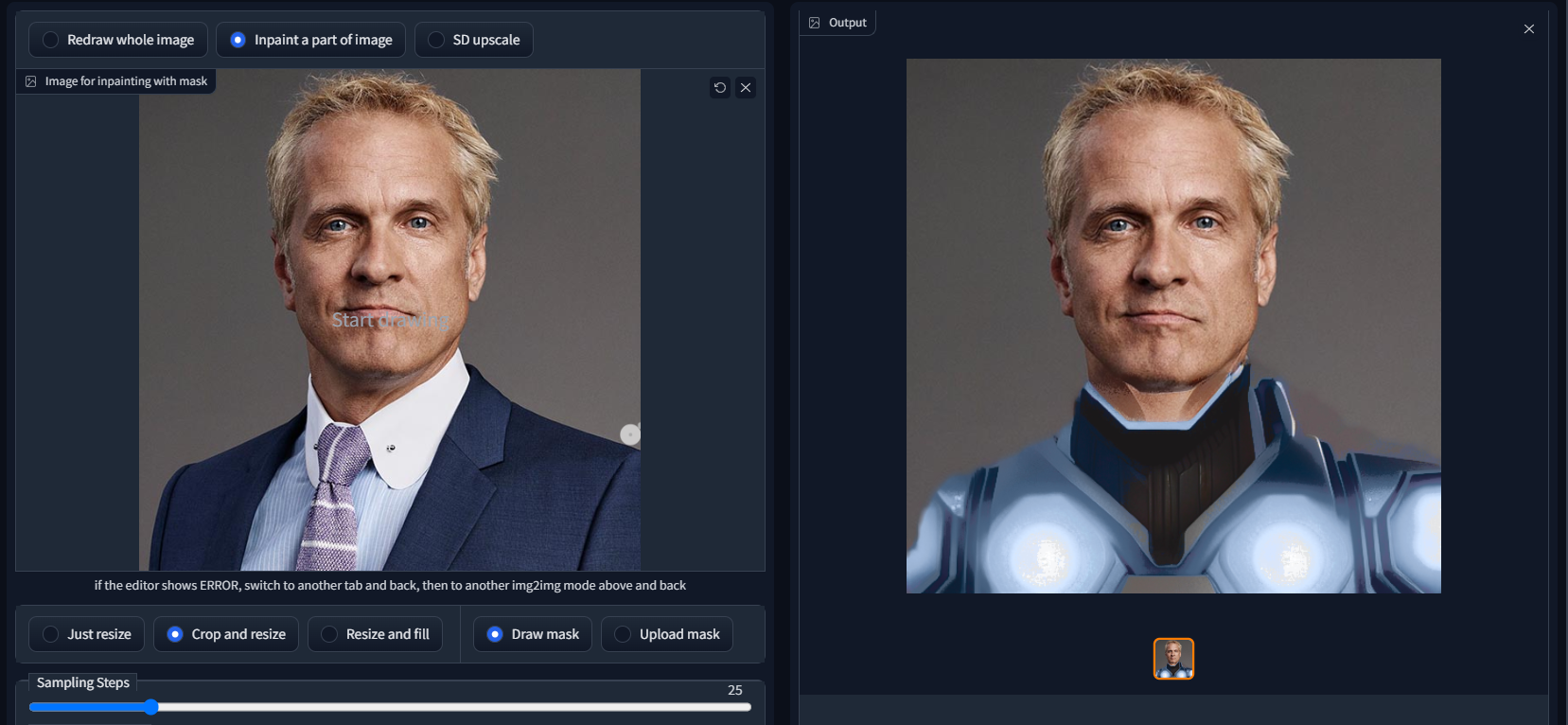
Mask drawing UI
https://github.com/dfaker/stable-diffusion-webui-cv2-external-masking-script
Provides a local popup window powered by CV2 that allows addition of a mask before processing.

Img2img Video
https://github.com/memes-forever/Stable-diffusion-webui-video
Using img2img, generates pictures one after another.
Seed Travel
https://github.com/yownas/seed_travel
Pick two (or more) seeds and generate a sequence of images interpolating between them. Optionally, let it create a video of the result.
Example of what you can do with it:
https://www.youtube.com/watch?v=4c71iUclY4U
Advanced Seed Blending
This script allows you to base the initial noise on multiple weighted seeds.
Ex. seed1:2, seed2:1, seed3:1
The weights are normalized so you can use bigger once like above, or you can do floating point numbers:
Ex. seed1:0.5, seed2:0.25, seed3:0.25
Prompt Blending
This script allows you to combine multiple weighted prompts together by mathematically combining their textual embeddings before generating the image.
Ex.
Crystal containing elemental {fire|ice}
It supports nested definitions so you can do this as well:
Crystal containing elemental {{fire:5|ice}|earth}
Animator
https://github.com/Animator-Anon/Animator
A basic img2img script that will dump frames and build a video file. Suitable for creating interesting zoom in warping movies, but not too much else at this time.
Parameter Sequencer
https://github.com/rewbs/sd-parseq
Generate videos with tight control and flexible interpolation over many Stable Diffusion parameters (such as seed, scale, prompt weights, denoising strength…), as well as input processing parameter (such as zoom, pan, 3D rotation…)
Alternate Noise Schedules
https://gist.github.com/dfaker/f88aa62e3a14b559fe4e5f6b345db664
Uses alternate generators for the sampler’s sigma schedule.
Allows access to Karras, Exponential and Variance Preserving schedules from crowsonkb/k-diffusion along with their parameters.
Vid2Vid
https://github.com/Filarius/stable-diffusion-webui/blob/master/scripts/vid2vid.py
From real video, img2img the frames and stitch them together. Does not unpack frames to hard drive.
Txt2VectorGraphics
https://github.com/GeorgLegato/Txt2Vectorgraphics
Create custom, scaleable icons from your prompts as SVG or PDF.
| prompt | PNG | SVG |
|---|---|---|
| Happy Einstein |  |
 |
| Mountainbike Downhill |  |
 |
| coffe mug in shape of a heart |  |
 |
| Headphones |  |
 |
Shift Attention
https://github.com/yownas/shift-attention
Generate a sequence of images shifting attention in the prompt.
This script enables you to give a range to the weight of tokens in a prompt and then generate a sequence of images stepping from the first one to the second.
Loopback and Superimpose
https://github.com/DiceOwl/StableDiffusionStuff
https://github.com/DiceOwl/StableDiffusionStuff/blob/main/loopback_superimpose.py
Mixes output of img2img with original input image at strength alpha. The result is fed into img2img again (at loop>=2), and this procedure repeats. Tends to sharpen the image, improve consistency, reduce creativity and reduce fine detail.
Interpolate
https://github.com/DiceOwl/StableDiffusionStuff
https://github.com/DiceOwl/StableDiffusionStuff/blob/main/interpolate.py
An img2img script to produce in-between images. Allows two input images for interpolation. More features shown in the readme.
Run n times
https://gist.github.com/camenduru/9ec5f8141db9902e375967e93250860f
Run n times with random seed.
Advanced Loopback
https://github.com/Extraltodeus/advanced-loopback-for-sd-webui
Dynamic zoom loopback with parameters variations and prompt switching amongst other features!
prompt-morph
https://github.com/feffy380/prompt-morph
Generate morph sequences with Stable Diffusion. Interpolate between two or more prompts and create an image at each step.
Uses the new AND keyword and can optionally export the sequence as a video.
prompt interpolation
https://github.com/EugeoSynthesisThirtyTwo/prompt-interpolation-script-for-sd-webui
With this script, you can interpolate between two prompts (using the “AND” keyword), generate as many images as you want. You can also generate a gif with the result. Works for both txt2img and img2img.

Asymmetric Tiling
https://github.com/tjm35/asymmetric-tiling-sd-webui/
Control horizontal/vertical seamless tiling independently of each other.

Force Symmetry
https://gist.github.com/1ort/2fe6214cf1abe4c07087aac8d91d0d8a
see https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/2441
applies symmetry to the image every n steps and sends the result further to img2img.

SD-latent-mirroring
https://github.com/dfaker/SD-latent-mirroring
Applies mirroring and flips to the latent images to produce anything from subtle balanced compositions to perfect reflections

txt2palette
https://github.com/1ort/txt2palette
Generate palettes by text description. This script takes the generated images and converts them into color palettes.

StylePile
https://github.com/some9000/StylePile
An easy way to mix and match elements to prompts that affect the style of the result.

XYZ Plot Script
https://github.com/xrpgame/xyz_plot_script
Generates an .html file to interactively browse the imageset. Use the scroll wheel or arrow keys to move in the Z dimension.
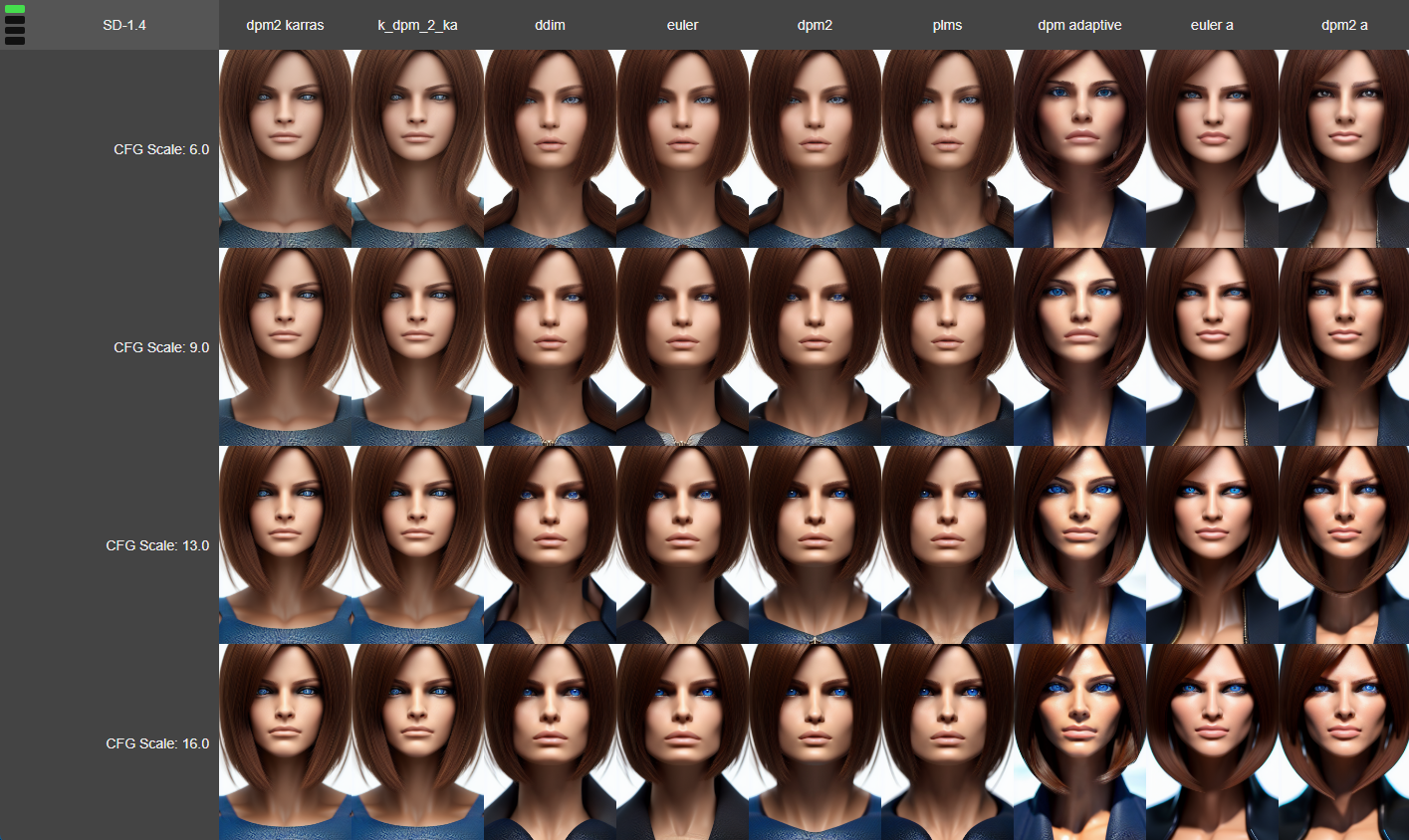
xyz-plot-grid
https://github.com/Gerschel/xyz-plot-grid
Place xyz_grid.py in scripts folder along side other scripts. Works like x/y plot, like how you would expect, but now has a z. Works like how you’d expect it to work, with grid legends as well.

Expanded-XY-grid
https://github.com/0xALIVEBEEF/Expanded-XY-grid
Custom script for AUTOMATIC1111’s stable-diffusion-webui that adds more features to the standard xy grid:
-
Multitool: Allows multiple parameters in one axis, theoretically allows unlimited parameters to be adjusted in one xy grid
-
Customizable prompt matrix
-
Group files in a directory
-
S/R Placeholder - replace a placeholder value (the first value in the list of parameters) with desired values.
-
Add PNGinfo to grid image

| Example images: Prompt: “darth vader riding a bicycle, modifier”; X: Multitool: “Prompt S/R: bicycle, motorcycle | CFG scale: 7.5, 10 | Prompt S/R Placeholder: modifier, 4k, artstation”; Y: Multitool: “Sampler: Euler, Euler a | Steps: 20, 50” |
Booru tag autocompletion
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
Displays autocompletion hints for tags from “image booru” boards such as Danbooru. Uses local tag CSV files and includes a config for customization.
Also supports completion for wildcards
Embedding to PNG
https://github.com/dfaker/embedding-to-png-script
Converts existing embeddings to the shareable image versions.

Alpha Canvas
https://github.com/TKoestlerx/sdexperiments
Outpaint a region. Infinite outpainting concept, used the two existing outpainting scripts from the AUTOMATIC1111 repo as a basis.

Random grid
https://github.com/lilly1987/AI-WEBUI-scripts-Random
Randomly enter xy grid values.

Basic logic is same as x/y plot, only internally, x type is fixed as step, and type y is fixed as cfg. Generates x values as many as the number of step counts (10) within the range of step1|2 values (10-30) Generates x values as many as the number of cfg counts (10) within the range of cfg1|2 values (6-15) Even if you put the 1|2 range cap upside down, it will automatically change it. In the case of the cfg value, it is treated as an int type and the decimal value is not read.
Random
https://github.com/lilly1987/AI-WEBUI-scripts-Random
Repeat a simple number of times without a grid.

Stable Diffusion Aesthetic Scorer
https://github.com/grexzen/SD-Chad
Rates your images.
img2tiles
https://github.com/arcanite24/img2tiles
generate tiles from a base image. Based on SD upscale script.

img2mosiac
https://github.com/1ort/img2mosaic
Generate mosaics from images. The script cuts the image into tiles and processes each tile separately. The size of each tile is chosen randomly.

Depth Maps
https://github.com/thygate/stable-diffusion-webui-depthmap-script
This script is an addon for AUTOMATIC1111’s Stable Diffusion Web UI that creates depthmaps from the generated images. The result can be viewed on 3D or holographic devices like VR headsets or lookingglass display, used in Render- or Game- Engines on a plane with a displacement modifier, and maybe even 3D printed.

Test my prompt
https://github.com/Extraltodeus/test_my_prompt
Have you ever used a very long prompt full of words that you are not sure have any actual impact on your image? Did you lose the courage to try to remove them one by one to test if their effects are worthy of your pwescious GPU?
WELL now you don’t need any courage as this script has been MADE FOR YOU!
It generates as many images as there are words in your prompt (you can select the separator of course).
Here the prompt is simply : “banana, on fire, snow” and so as you can see it has generated each image without each description in it.

You can also test your negative prompt.
Pixel Art
https://github.com/C10udburst/stable-diffusion-webui-scripts
Simple script which resizes images by a variable amount, also converts image to use a color palette of a given size.
| Disabled | Enabled x8, no resize back, no color palette | Enabled x8, no color palette | Enabled x8, 16 color palette |
|---|---|---|---|
 |
 |
 |
 |
japanese pagoda with blossoming cherry trees, full body game asset, in pixelsprite style
Steps: 20, Sampler: DDIM, CFG scale: 7, Seed: 4288895889, Size: 512x512, Model hash: 916ea38c, Batch size: 4
Multiple Hypernetworks
https://github.com/antis0007/sd-webui-multiple-hypernetworks
Adds the ability to apply multiple hypernetworks at once. Overrides the hijack, optimization and CrossAttention forward functions in order to apply multiple hypernetworks sequentially, with different weights.
Hypernetwork Structure(.hns)/Variable Dropout/ Monkey Patches
https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extension
Adds the ability to apply Hypernetwork Structure, as defining it in .hns file. see here for detailed information.
Adds the ability to use proper variable dropout rate, like 0.05. Also fixes issues with using hypernetwork right after training.
Adds creating beta-hypernetwork(dropout), and beta-training which allows automatic cosine annealing, and no-crop usage of original images.
Config-Presets
https://github.com/Zyin055/Config-Presets-Script-OLD
Quickly change settings in the txt2img and img2img tabs using a configurable dropdown of preset values.
Saving steps of the sampling process
This script will save steps of the sampling process to a directory.
import os.path
import modules.scripts as scripts
import gradio as gr
from modules import sd_samplers, shared
from modules.processing import Processed, process_images
class Script(scripts.Script):
def title(self):
return "Save steps of the sampling process to files"
def ui(self, is_img2img):
path = gr.Textbox(label="Save images to path")
return [path]
def run(self, p, path):
index = [0]
def store_latent(x):
image = shared.state.current_image = sd_samplers.sample_to_image(x)
image.save(os.path.join(path, f"sample-{index[0]:05}.png"))
index[0] += 1
fun(x)
fun = sd_samplers.store_latent
sd_samplers.store_latent = store_latent
try:
proc = process_images(p)
finally:
sd_samplers.store_latent = fun
return Processed(p, proc.images, p.seed, "")